One of the challenges smaller firms face in creating ETL or BI solutions that deliver, is in testing.
Whilst application developers have been doing continuous integration (CI) and automated testing for long enough that it’s now mainstream, in the reporting world, the landscape is different…
Reporting teams are often just one or two strong. For some reason, they’re often an afterthought and it’s often left to an overworked individual to develop and test as a manual job meaning that coverage and quality can be inconsistent at best and non existent if the requirement is urgent enough.
But thankfully there are tools and development patterns out there that can do much of this work for you.
A combination of SQL Server Data Tools projects (For Microsoft platform), a CI server (Azure, Jenkins or Bamboo all offer lots of features at different price points) and version control (Git, SVN & TFS are all widely used and compatible with most build servers) means that you can set up a development environment that automates much of the testing.
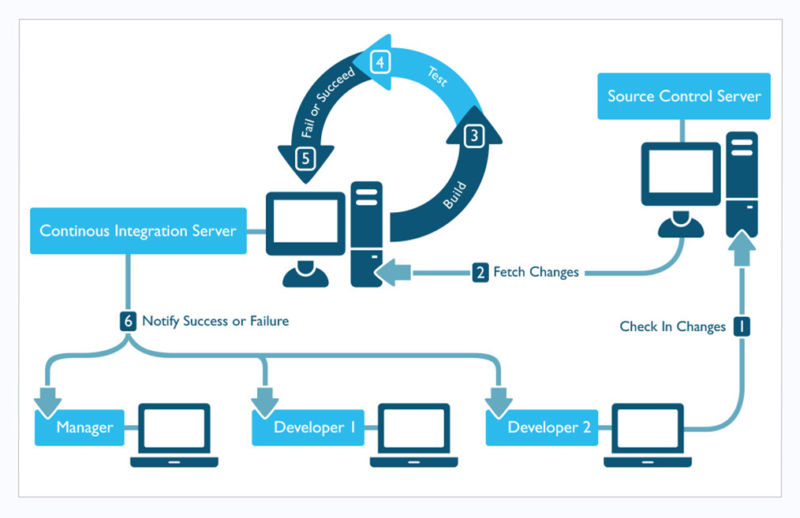
A typical pattern for database CI would involve:
- Scheduling the transfer of production backups to a development server
- Creating jobs on CI Server that are triggered by a check in on your version control system which should perform:
- A build: this job should attempt to build the entire solution including running any tests that are included in it. MSBuild will use the schema as defined in your projects, so at this point you may be notified of code analysis, compilation, code integration or failed dependency errors. Success here would trigger a new job…
- A deployment: assuming a successful build, this next job should restore a production database, and using the successful build from previous step, deploy over the top of the newly restored database. This is where you will be notified of run time errors, data constraint issues, and other deployment problems.
- Running a batch against the new change-set. It should be scheduled to run overnight if it’s a long running batch or more frequently if it’s a quicker job.
- Creating appropriate feedback mechanisms. This could be via email; integration between ticketing systems, CI server and source control; or even light’s that changes colour according to health of the build.
Some of this might seem like overkill, but the idea here is simply to define, grow and automate a set of quality tests whilst at the same time reducing the time it takes to feedback any failures to the developer so they can act on them. Given this is the first time the developer has exposed their code to a wider set of systems, this is where we try to eliminate the “it worked on my machine” errors.
None of this is new in application development, but in my experience in the database world, this is often neglected. It shouldn’t be.
A nice explainer on the subject of CI here: https://www.exoscale.com/syslog/what-is-continuous-integration/